Entry for the 2026 XDU Spark Cup Agent Development Competition
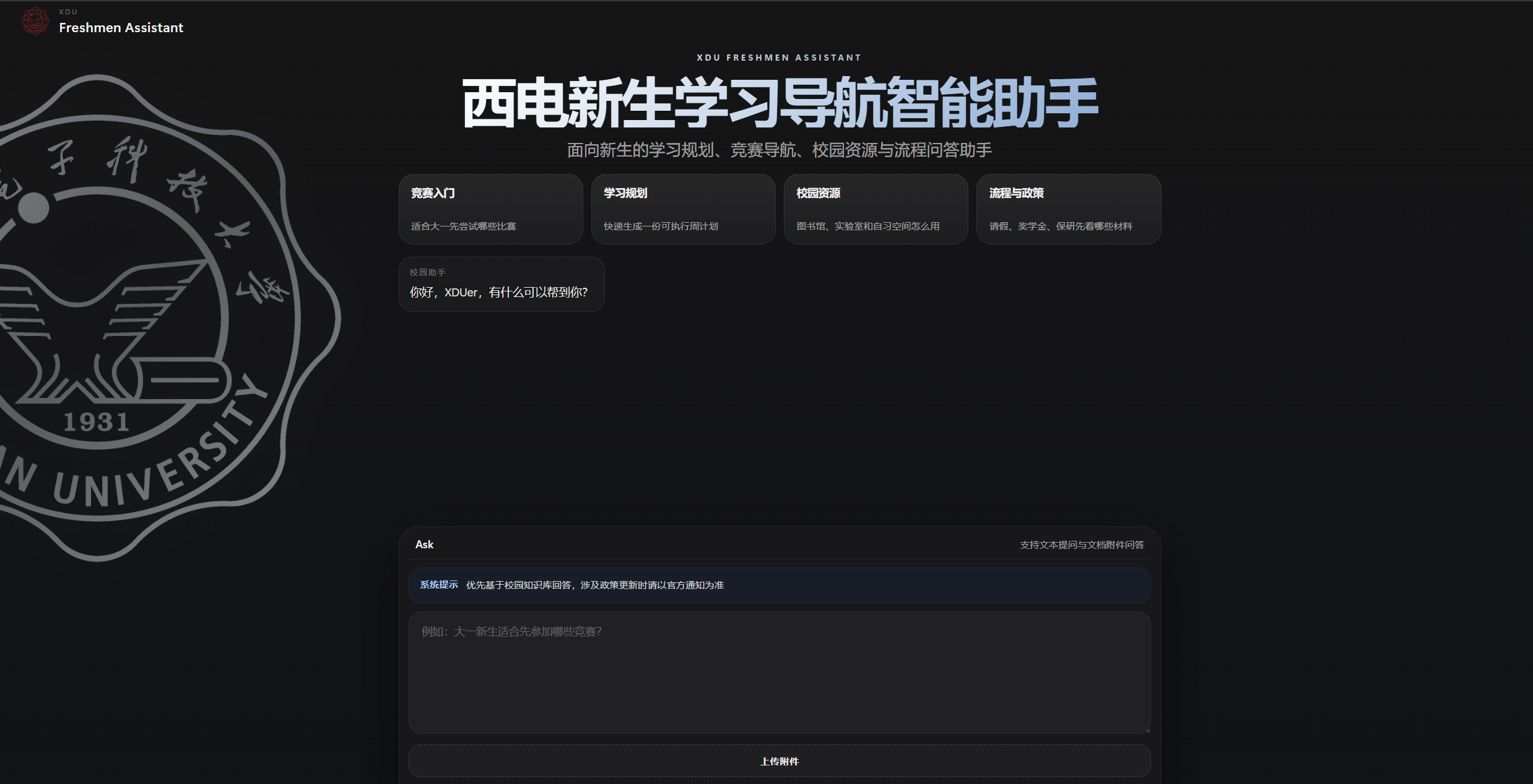
XDU Freshmen Assistant
A campus QA project for first-year students at Xidian University
The project has completed local prototyping and launched an initial cloud release. Users now only need to open a single web page in the browser to access campus Q&A and document-based questioning. The current scope focuses on onboarding, study planning, competition entry, campus resources, and routine procedure guidance.
Project Background
Project Need
The project is designed for first-year students at Xidian University. For freshmen, the core issue is not a total lack of information, but the fact that campus information is scattered across department notices, chat groups, academic affairs pages, experience posts, and loose documents. Students often need to handle onboarding, study planning, competition entry, resource access, and routine procedures at the same time, so a single dialogue-based entry point is needed.
- Information sources are scattered during onboarding, making it hard to decide what to read and do first
- Training schemes, course plans, and study priorities are not easy to interpret at the beginning
- Competition directions are numerous, yet freshmen still need clearer beginner-oriented guidance
- Campus resources and routine procedures still require too much manual searching
Functional Overview
Core Functions
The current release is already online, and the frontend, backend, knowledge base, and baseline engineering path have all been connected.
Text-based Q&A
Users can type questions directly in the browser, with current coverage focused on onboarding, study planning, competitions, campus resources, and routine procedures
Conversation Interaction
The interface supports new chat reset, quick prompt cards, and a more natural streaming-style output to reduce context carryover and improve the basic dialogue experience
Markdown Rendering
The frontend correctly renders headings, lists, code blocks, and tables, making longer and more structured answers easier to read
Document Text Q&A
The system accepts common document formats such as PDF, DOCX, XLSX, PPTX, and TXT, extracts their text, and supports follow-up questions about the uploaded content
Knowledge-first Answering
The backend follows a local-knowledge-first strategy: it retrieves and summarizes local materials first, then uses Coze capability as a supplement
Source Type Hints
Answers retain user-facing source hints, such as public library guidance notes.
Technical Structure
Main Technical Path
The current system uses a hybrid architecture: static frontend page + cloud Python backend + local knowledge augmentation + Coze capability supplement. The online version has already been built into a complete browser-accessible QA flow.
Handles the chat interface, input area, quick prompts, Markdown rendering, attachment upload, and chat reset.
Provides OpenAI-compatible endpoints for chat, attachment text extraction, and service health checks.
Loads, retrieves, and summarizes locally curated campus materials before final response generation.
Supplies the external generation layer after local knowledge has already provided the primary grounding.
Used for chat UI, quick prompts, attachment upload, streaming output, and Markdown rendering.
Handles the main chat requests, document text extraction, and baseline service health checks for the frontend.
The knowledge base covers freshman Q&A, campus resources, procedures, study guidance, competitions, and public program information.
The online release runs on a cloud server, with Nginx, systemd, and HTTPS covering public access, process uptime, and basic security.
Baseline checks already cover health, chat response shape, attachment extraction, and knowledge loading and retrieval.
Current Status
Current Delivery Status
Initial Cloud Release
The project has completed a cloud deployment, and users can directly access the frontend and use the core QA functions
End-to-end QA Flow
Frontend, backend, local knowledge support, and Coze capability supplement have been integrated into one usable path
Document Text Handling
The online version already supports document text extraction and follow-up questioning over the extracted content
Deployment and Security Baseline
Nginx, systemd, HTTPS, server-side environment variables, and localhost-only backend listening have all been set in place
Baseline Engineering Support
The repository already includes baseline tests and GitHub Actions CI, so the project is beyond a bare runnable prototype
Current Positioning
The project is stable enough for demonstration and online access, but it is not yet positioned as a long-term public commercial system; time-sensitive information should still follow the latest official notices from the university and departments.
Demo / Usage
Online Version Demonstration
The video corresponds to the current browser-accessible release path. It can be played directly on this page and viewed together with the proposal as supporting context.
Recorded usage flow corresponding to the current cloud release, playable directly on the page.
Future Work
Planned Improvements
- Add stronger annual verification and refresh mechanisms for time-sensitive policy and scholarship information.
- Continue structuring the knowledge base and strengthen retrieval, summarization, and citation stability.
- Evaluate OCR, scanned-document support, and broader multimodal enhancement beyond the current text-only attachment path.
- Improve long-term public deployment support with better monitoring, traffic control, and operational visibility.
- Keep the current lightweight online path stable while gradually extending the fuller agent-oriented engineering branch.